
Stock Trading With Cooldown
Get started
জয় শ্রী রাম
🕉Problem Statement:
Say you have an array for which the ith element is the price of a given stock on day i.Design an algorithm to find the maximum profit. You may complete as many transactions as you like (ie, buy one and sell one share of the stock multiple times) with the following restrictions:
You may not engage in multiple transactions at the same time (ie, you must sell the stock before you buy again).
After you sell your stock, you cannot buy stock on next day. (ie, cooldown 1 day)
Example:
Input: [1,2,3,0,2]
Output: 3
Explanation: transactions = [buy, sell, cooldown, buy, sell]
Solution:
- Finite state machines are a standard tool to model event-based control logic. If a given problem contains different events and depending on which event occurs we can transition from one state to another then it is highly likely that the problem could be solved using Dynamic Programming State Machine approach.
State Machine is a powerful technique which once you have command over it you would be able to unleash its power to solve numerous complex problems very easily. State Machine is a natural fit for Dynamic Programming. In State Machine a state transforms into another. The fact that the transformed state uses result from previous state demonstrates optimal substructure property.
State Machines consist of two main concept:
- States which are represented with nodes in State machine diagrams. States are generally nouns or adjectives or some boolean (like, hasStock).
- Activities which mark how one state transitions to another (i.e, state transition due to which activity ?). Activities are represented with directed edges in State Machine Diagram. Activities are generally verbs.
State Machine Activities:
If you spend some time thinking through the problem, you would be able to figure that there are three activities in the given problem:
- Buy Stock
- Sell Stock
- Cooldown
States:
- Buy Stock activity would lead you to having one stock with you.
- Sell Stock activity would lead you to have no stock with you.
- Cooldown would lead you to have no stock with you.
It is very important to have a crisp understanding of what the activities actually indicate and when they are applicable (for example, in the given problem cooldown activity is applicable only after a sale activity has been executed). Buy Stock indicates buying a stock, but when ? If an activity directed edge indicating activity A goes from state S1 to state S2, then for this problem that would mean doing the activity the next day of the day we were in state S1. So S2 is the state of the next day only when the previous day we were in state S1 and we know that we transitioned to S2 from S1 (and not fro any other state, because in some cases one state can be reached from multiple other states, so we need to know exactly from which state we are transitioning from). And this transition was possible by executing activity A on that "next day".
So we can see that we have three states here:
- hasStock
- noStock
- cooldownDone
Now the tricky part here: even the state cooldownDone indicates "no stock". So we need a better name either for noStock state or for cooldownDone state. If you think through the problem you would decipher that: broadly we have two states here: "has stock" and "no stock at hand". Now, "no stock at hand" situation again has two sub-states: (1) we can reach to "no stock at hand" state by selling today (we cannot buy a stock in this state), or (2) by cooling down for a day after a stock sale event (we are eligible to buy a stock in this state). So, let's call the later state "noStock" state and the former "justSold" state.
The above discussion leads us to having the below three states instead:
- hasStock
- justSold
- noStock
If we are at hasStock on a certain day, we can still remain in the same state the day after if we do nothing the next day. Same can be said for noStock state as well. However, this is not true for justSold state. When we do nothing the next day of selling a stock (and that is the only valid action for the day after selling a stock) we transition to noStock state.
Do Nothing = Make no transaction, i.e, Take Rest
Below is the state machine diagram:
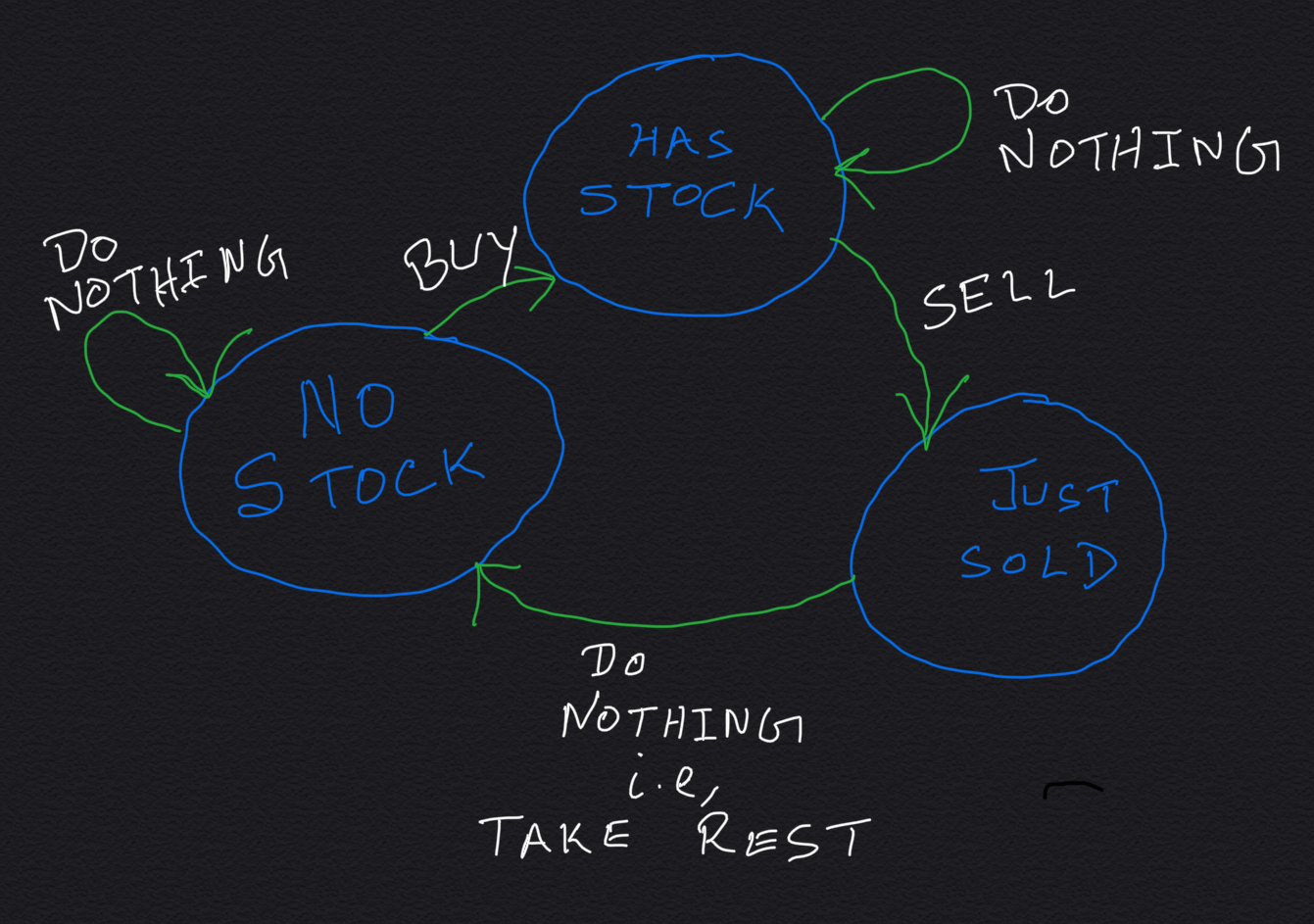
DP Relation:
The main challenge in State Machine approach is to draw the state machine diagram correctly. Once we have done that, transforming the state machine diagram into a Dynamic Programming Recurrence Relation is just a piece cake. A logical thinking also gives the base condition very easily.
- For the base condition it is very important to identify which are the states that can the start state. All other states need to mark as impossible (programmatically).
- For getting the final DP result, it is very important to identify which are the states we can be in on the last day in order to get optimal result.
In the DP relations:
- hasStock[i] denotes maximum profit achievable at the end of day i (zero-based index), if we choose to buy a stock on day i.
- noStock[i] denotes maximum profit achievable at the end of day i (zero-based index), if we choose to make no transaction at all on day i.
- justSold[i] denotes maximum profit achievable at the end of day i (zero-based index), if we choose to sell a stock on day i.
noStock[day] = Max(noStock[day - 1], justSold[day - 1])
hasStock[day] = Max(noStock[day - 1] - prices[day], hasStock[day - 1])
justSold[day] = hasStock[day - 1] + prices[day]
Base Condition: On the first day we cannot be in justSold state because we have no stock to sell, but we can start with buying a stock, so hasStock is a valid state for the first day. Also, we can choose to do nothing on the first day (i.e, not making any transaction, which means not buying any stock on the first day). In that case we are on noStock state.
So, noStock state is the START state, and hasStock and noStock states are the only valid states for the first day.
This leads us to formulate the base cases as follows:
-
hasStock[0] = -prices[0];
Reason: If we acquire a stock on first day, then we will have negative prices[0] as profit, i.e, no profit at all in fact loss of amount equal to prices[0] AT THE END OF FIRST DAY.
-
noStock[0] = 0;
Reason: Basically noStock state on first day means no transaction at all which means doing nothing on first day which means 0 net profit AT THE END OF THE FIRST DAY.
-
justSold[0] = Integer.MIN_VALUE;
Reason: Selling on first day is not possible. since we are optimizing for max profit we will mark this as Integer.MIN_VALUE to show that this state is impossible on first day.
Return Value:
We are optimizing for maximum profit we cannot hold a stock on the last day. The last day should end with no stock at hand. So on the last day (1) we can either sell a stock (if we already have one stock with us) and be in justSold state , (2) otherwise, we just do nothing, which is noStock state. Since our goal is to maximize profit, we take of maximum of noStock value and justSold value for last day.
So the return value is
Max(noStock[n - 1], justSold[n - 1])
Java Code:
Login to Access Content
Python Code:
Login to Access Content
Space Optimization:
We have room for Space Optimization in the above code because we do NOT need the noStock[], hasStock[] and justSold[] arrays due to our below observation:
-
In the for loop notice that for every day = i we are relying on
noStock[i - 1], hasStock[i - 1] and justSold[i - 1].
At no point of time we are using anything more than that and so having the whole arrays in memory is adding no value when we are dependent on just these three values
So what we can do is we can take three variables that would hold the value of noStock[i - 1], justSold[i - 1] and hasStock[i - 1] when we are processing for day = i.
The below code how we can optimize the above code:
Java Code:
Login to Access Content
Python Code:
Login to Access Content
How would you Compute Optimal DP Path ?
Our goal now is to print the days we would be purchasing a stock and the days we would be selling the stock that would maximize the profit.
In almost all the DP problems, finding the path that resulted in the optimal result takes little bit more thinking than just computing the optimal value. For our case, it would be finding the purchase days and selling days that led us to get the maximum profit.
It is always a good idea to first design the algorithm to compute the optimal value and then modify the code to find the optimal path. In most cases you would need the logic you implemented to compute the optimal result, to compute the optimal path. We will see that in the below well-commented code.
Thought process involved in the solution:
While reading the explanation below, please keep the state machine diagram in mind all the time. That would really help in understanding.
It is very easy to come up with the algorithm to find the days to buy and sell stocks from the state machine diagram. We buy a stock only when we transition from noStock state to hasStock. We sell a stock only when we transition to justSold state from hasStock state.
On any given day maximum profit can come either from justSold state or noStock state. When we get the maximum profit from noStock day we just return the already found purchase days and selling days. They don't change. But when we get maximum profit from justSold state, we need to know when this stock was bought. In the code you will see we are keeping an array tempPurchaseDays[] to store the day of last stock purchased that would maximize hasStock state for a day. That way when we sell a stock on say day i we can grab the purchase day for the just sold stock from tempPurchaseDays[i - 1]. Let's look at the code and the inline comments and everything just discussed will become crystal clear.
Java code:
Login to Access Content
Python code:
Login to Access Content
Don't forget to look at the other problems in our State Machine Approach series to have a strong understanding and a good command of this concept:
- Stock Trading With Transaction Fee
- Max Profit w/ at most 2 Stock Trade Transactions
- Max Profit w/ at most K Stock Trade Transactions
- Max Profit w/ Unlimited Stock Trade Transactions
- Max Profit w/ at most 1 Stock Trade Transaction
